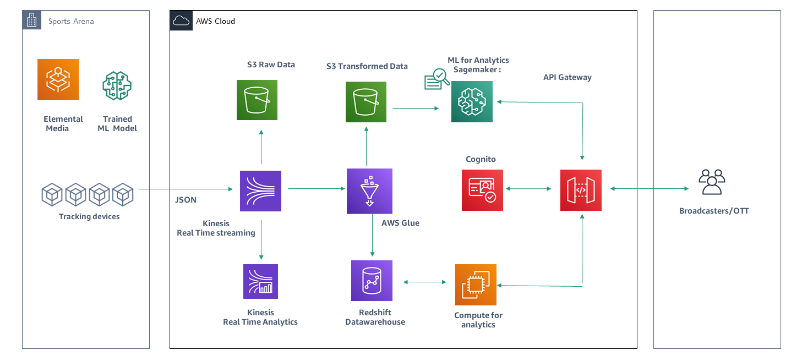
Introduction
In today’s data-driven world, businesses rely heavily on data pipelines to transform raw data into valuable insights. An effective data pipeline on AWS (Amazon Web Services) not only ingests data from multiple sources but also optimizes and transforms it to meet the diverse needs of data consumers. Building such a pipeline requires a deep understanding of both the technical aspects of data processing and the specific requirements of your organization.
This tutorial will guide you through the entire process of architecting an AWS data pipeline, from the initial whiteboarding session to a hands-on implementation. We’ll cover essential topics such as identifying data consumers and their needs, sourcing and ingesting data, performing necessary transformations, and loading data into data marts for consumption. By the end of this guide, you’ll have a solid understanding of how to design and build a data pipeline that not only meets your organization’s current needs but is also scalable and adaptable for future requirements.
Architecting a Data Pipeline
When approaching the task of architecting a data pipeline on AWS, consider the following steps:
- Understand the Business Context: Know the goals and objectives behind building the data pipeline.
- Define the Data Flow: Visualize the entire process from data ingestion to consumption.
- Select Appropriate AWS Services: Choose the right combination of AWS services for each stage of the pipeline.
- Ensure Scalability and Reliability: Design for high availability and scalability from the outset.
- Incorporate Security Best Practices: Implement security measures to protect data at every stage.
Identifying Data Consumers and Understanding Their Requirements
To build a data pipeline that effectively serves your organization, start by identifying the end-users or data consumers:
- Types of Data Consumers:
- Data analysts
- Business intelligence (BI) tools
- Data scientists
- Machine learning models
- Understanding Requirements:
- Data Formats: Identify the preferred formats (e.g., CSV, JSON, Parquet).
- Data Frequency: Determine how often data needs to be updated.
- Performance Expectations: Understand the latency and throughput requirements.
- Security and Compliance: Consider data access permissions and compliance needs.
Identifying Data Sources and Ingesting Data
Next, identify the data sources that will feed into your pipeline:
- Common Data Sources:
- Relational databases (e.g., MySQL, PostgreSQL)
- NoSQL databases (e.g., DynamoDB, MongoDB)
- External APIs
- Flat files (e.g., CSVs, log files)
- Streaming data sources (e.g., Kinesis, Kafka)
- Data Ingestion Methods:
- Batch Processing: Use AWS Glue, AWS Data Pipeline, or Lambda for periodic data ingestion.
- Real-Time Processing: Utilize AWS Kinesis, AWS IoT, or Amazon MSK for streaming data ingestion.
- File-Based Ingestion: Leverage AWS S3 for storing and processing flat files.
Data Transformation and Optimization
Once the data is ingested, it needs to be transformed and optimized to meet the needs of data consumers:
- Data Transformation:
- Cleaning: Handle missing values, remove duplicates, and normalize data.
- Enrichment: Integrate external data sources to add value.
- Aggregation: Summarize data to provide higher-level insights.
- Optimization:
- Partitioning: Divide large datasets for efficient querying and processing.
- Indexing: Improve query performance by creating indexes on frequently accessed columns.
- Compression: Use data compression to reduce storage costs and improve I/O performance.
- Tools and Services:
- AWS Glue for ETL (Extract, Transform, Load)
- AWS Lambda for serverless transformations
- Amazon Redshift for data warehousing and advanced analytics
Loading Data into Data Marts
Data marts are specialized storage solutions tailored to specific data consumers:
- Designing Data Marts:
- Subject-Oriented: Organize data based on key business areas (e.g., sales, marketing).
- Schema Design: Use star schema or snowflake schema for efficient querying.
- AWS Services:
- Amazon Redshift: Ideal for large-scale data marts and complex queries.
- Amazon RDS: Use for transactional data marts with high concurrency.
- Amazon S3: Store large volumes of raw or transformed data at low cost.
- Best Practices:
- Ensure data consistency between the data lake and data marts.
- Regularly update data marts to reflect the latest available data.
- Optimize data marts for query performance and user accessibility.
Wrapping Up the Whiteboarding Session
Before diving into implementation, summarize your architecture:
- Review Data Flow: Ensure each step in the pipeline is logically connected.
- Validate Service Choices: Confirm that the selected AWS services meet the pipeline’s needs.
- Consider Future Scalability: Design with future data volume and complexity in mind.
- Document Key Decisions: Keep a record of the architecture for future reference and team alignment.
Hands-On: Architecting a Simple AWS Data Pipeline
Now, let’s walk through building a simple data pipeline:
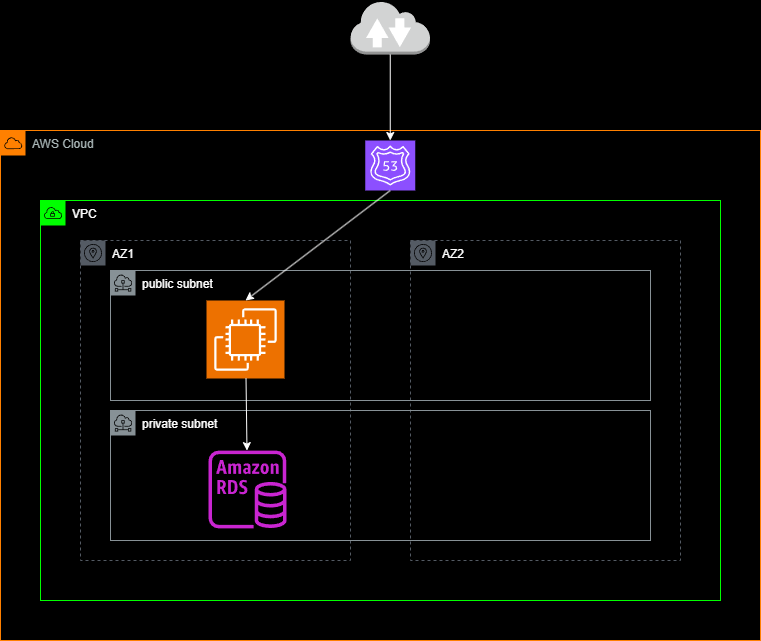
- Step 1: Set Up Data Sources:
- Create a sample MySQL database in Amazon RDS.
- Upload sample CSV files to an S3 bucket.
- Step 2: Ingest Data:
- Use AWS Glue to extract data from RDS and S3.
- Set up an AWS Kinesis Data Stream for real-time ingestion.
- Step 3: Transform Data:
- Create an AWS Glue job to clean and transform the data.
- Use AWS Lambda for lightweight data transformations.
- Step 4: Load Data into a Data Mart:
- Configure an Amazon Redshift cluster.
- Load the transformed data into Redshift tables.
- Step 5: Query and Analyze Data:
- Use Amazon QuickSight or a BI tool to visualize the data.
Conclusion
Building a robust data pipeline on AWS requires careful planning, a deep understanding of your data consumers’ needs, and the right combination of AWS services. By following this tutorial, you should now have the knowledge to architect and implement a scalable data pipeline that effectively ingests, transforms, and delivers data to your organization’s stakeholders. As data volumes grow and business requirements evolve, the flexibility and scalability of AWS will ensure your pipeline continues to meet your organization’s needs.
Investing time in properly architecting your data pipeline will pay off in better data quality, faster insights, and more informed decision-making. Start building your AWS data pipeline today, and unlock the full potential of your organization’s data.